手机网站
手机网站
手机网站
手机网站
在很多二分类问题中,特别是正负样本不均衡的分类问题中,常使用交叉熵作为loss对模型的参数求梯度进行更新,那为何交叉熵能作为损失函数呢,我也是带着这个问题去找解析的
简介:语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从
交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距。以前做一些分类问题的时候,没有过多的注意,直接调用现成的库,用起来也比较方便。
交叉熵容易跟相对熵搞混,二者联系紧密,但又有所区别。假设有两个分布 ,则它们在给定样本集上的交叉熵定义如下: 可以看出,交叉熵与上一节定义的相对熵仅相差了 已知时,可
通常使用的平滑技术有图灵估计、删除插值平滑、Katz平滑和Kneser-Ney平滑。 歧义问题的描述和消除问题是制约计算语言学发展的瓶颈问题.将交叉熵引入计算语言学消岐领
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵
可以看出,交叉熵与上一节定义的相对熵仅相差了H(p),当p已知时,可以把H(p)看做一个常数,此时交叉熵与KL距离在行为上是等价的,都反映了分布p,q的相似程度。最小化交叉熵
交叉熵有一个标准的解释,它来自信息论(information theory),粗略地说,交叉熵是表达惊奇(surprise)的一个度量。在实际中,我们的神经元尝试计算函数xày=y(x)。只是一般写成xà
因此,交叉熵越低,这个策略就越好,最低的交叉熵也就是使用了真实分布所计算出来的信息熵,因为此时 ,交叉熵 =信息熵。这也是为什么在机器学习中

基于交叉熵的出租车资源合理配置.PDF
800x1131 - 278KB - PNG

基于交叉熵的病毒式移动通信系统性能研究-控
800x1131 - 71KB - PNG

交叉熵相似性度量在水文时间序列匹配中的应用
800x1098 - 360KB - PNG

交叉熵图像处理.ppt
1280x720 - 113KB - PNG

基于交叉熵理论的配电变压器寿命组合预测方法
800x1131 - 60KB - PNG

基于交叉熵的正态分布区间数多属性决策方法.
800x1156 - 367KB - PNG
【读懂深度学习中的代价函数、交叉熵】- 一点
469x501 - 33KB - JPEG
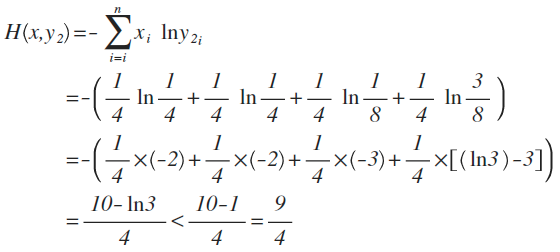
归一化(softmax)、信息熵、交叉熵
560x252 - 26KB - PNG
简单易懂的softmax交叉熵损失函数求导
640x231 - 8KB - JPEG

交叉熵(cross-entropy)探讨_「电脑玩物」中文
604x485 - 42KB - JPEG

基于局部交叉熵的图像匹配跟踪算法_word文档
1280x1869 - 866KB - PNG

基于局部交叉熵的图像匹配跟踪算法_word文档
1280x1869 - 497KB - PNG

运动目标检测--改进的背景减法 - 综合编程类其
540x232 - 68KB - JPEG
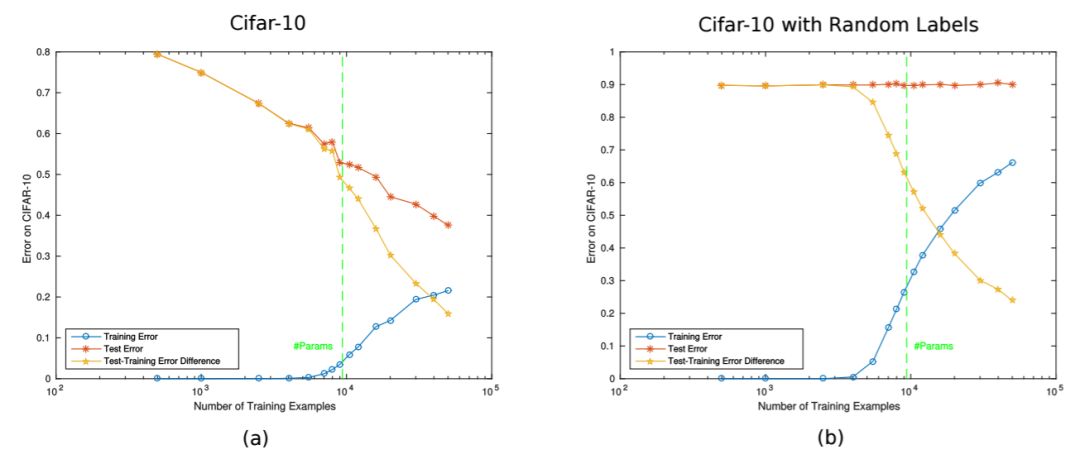
学界 | Tomaso Poggio深度学习理论:深度网络「
1080x464 - 36KB - JPEG

交叉熵(cross-entropy)探讨_「电脑玩物」中文
589x400 - 72KB - JPEG