手机网站
手机网站
手机网站
手机网站
老遇到交叉熵作为损失函数的情况,于是总结一下 KL散度交叉熵从KL散度(相对熵)中引出,KL散度(Kullback-Leibler Divergence)公式为: KL散度是衡量两个分布之间的差异大小的
交叉熵和熵,相当于,协方差和方差相对熵相对熵考察两个信息(分布)之间的不相似性:所谓相对,自然在两个随机变量之间。又称互熵,Kullback–Leibler divergence(K-L散度)等。设
又因为该问题中,真实的概率分布P是已知的,而且在整个训练过程中是不变的,所以这个H(p)是一个定值,那么此时最小化KL散度也就是最小化p与q的交叉熵了,当然这个也等价于
值域为[0,1],相等时为0,相对KL散度来说更精确。 参考文献: 还能输入1000个字符 先插入一个链接可视化信息论,简单明了很容易看懂什么是信息熵信息熵是度量随机变量不确定
当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代 KL散度(Kullback–Leibler divergence,KLD) Kullback–Leibler divergence。它表示2个函
$D_{KL}(P||Q)$表示两个分布的 KL散度。当概率分布 $P(\text{x})$确定了时,$H(P)$也将被确定,即 $H(P)$是一个常数。在这种情况下,交叉熵和 KL散度就差一个大小为 $H(P)$的
训练时,针对某一个标签信息y(x)是已知的,所以讲KL(y(x)||y^~(x))中的H(y(x))是个常数,此时KL散度等价于交叉熵,所以交叉熵可以衡量p(x)与q(x)的差异,我们希望q(x)尽可能地接近p
{KL}(p_{data}||p_{model})=E_{\mathsf{x}\sim p_{data}}\left[ \log p_{data}-\log p_{model}(x) \right]$$而最小化KL散度又等价于最小化分布之间的交叉熵$$-E_{\mathsf{x}\sim p_{da
https://www.youtube.com/作者:Aurélien Géron转载自:https://www.youtube.com/watch?v=ErfnhcEV1O8【深度学习 】熵,交叉熵,KL散度 Entropy,
信息量,信息熵,交叉熵,KL散度和互信息(信息增益)转载 您需要登录后才可以回帖 GMT+8, 2019-3-13 07:43 , Processed in 0.125573 second(s), 28 queries . 公众号 小程序 版权
生成对抗网络(GANs)系列文章之一:KL散度和J
640x452 - 33KB - JPEG
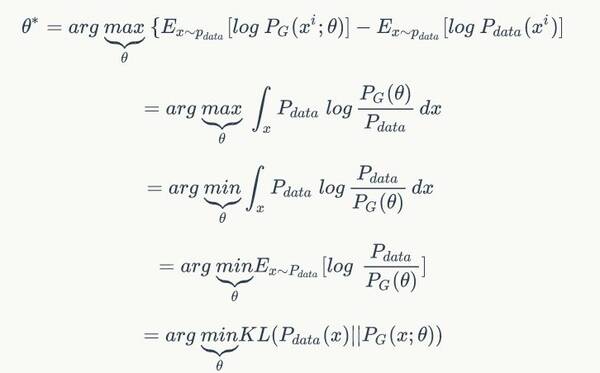
机器学习各种熵:从入门到全面掌握
600x373 - 18KB - JPEG
如何理解KL散度的不对称性?
180x135 - 3KB - PNG

来聊聊最近很火的WGAN
626x336 - 40KB - PNG

Deep Learning」读书系列分享第三章:概率和信
640x359 - 35KB - JPEG
Deep Learning」读书系列分享第三章:概率和信
740x414 - 38KB - JPEG

从香农熵到手推KL散度:一文带你纵览机器学习
800x571 - 19KB - JPEG
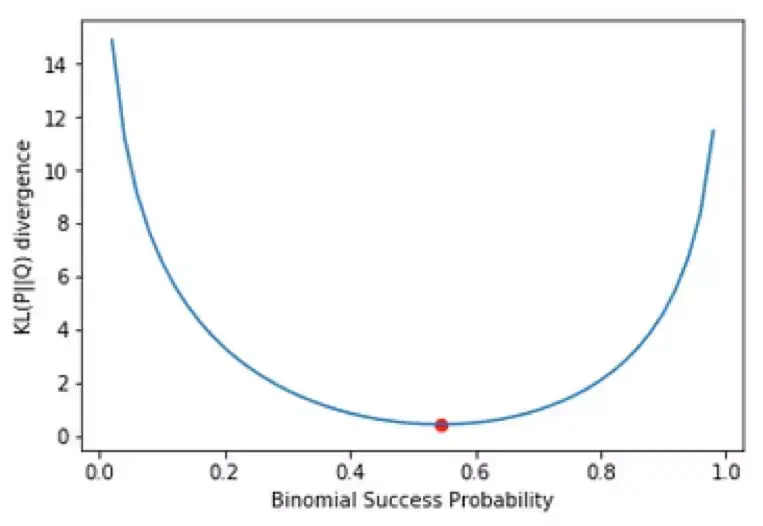
计算 KL 散度
763x526 - 32KB - JPEG

从香农熵到手推KL散度:一文带你纵览机器学习
1200x428 - 47KB - JPEG

如何理解KL散度的不对称性?
640x264 - 14KB - JPEG
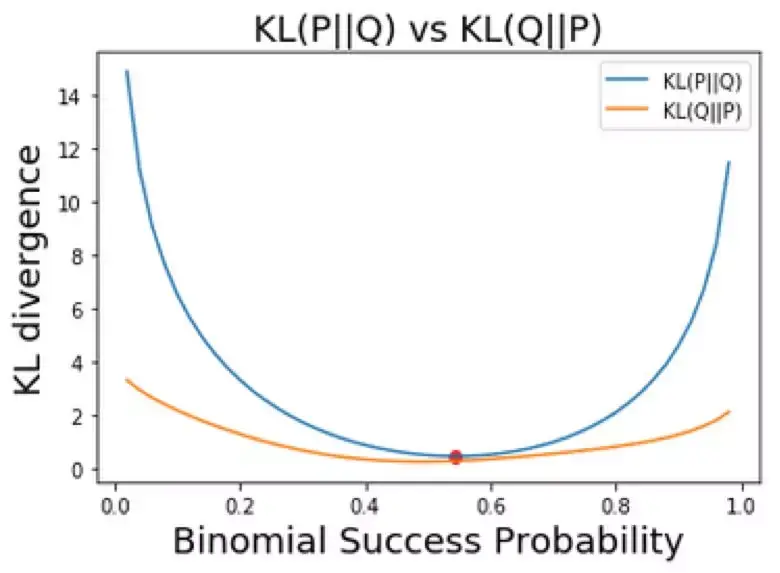
计算 KL 散度
780x573 - 54KB - JPEG
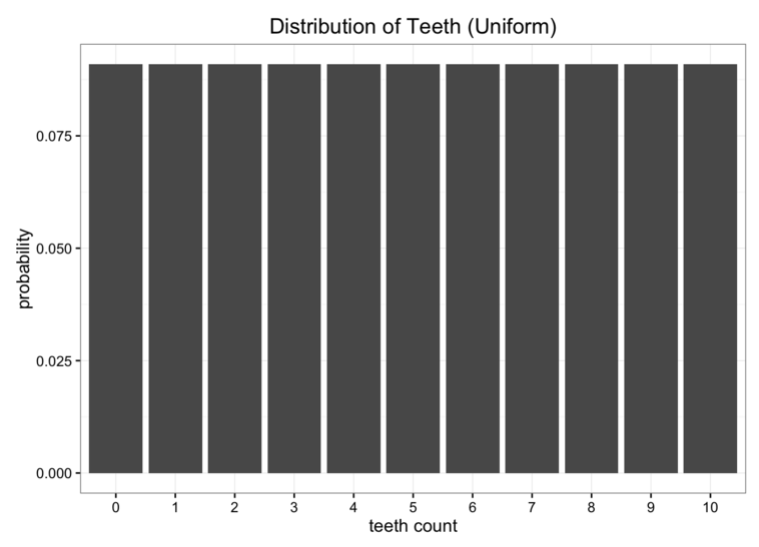
KL散度在各领域不同的使用情况
759x547 - 14KB - PNG
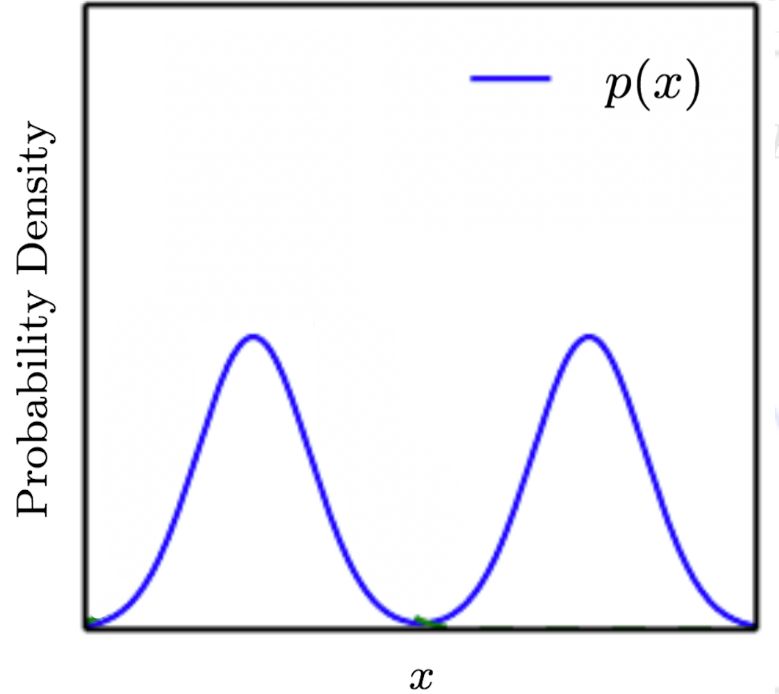
教程 | 如何理解KL散度的不对称性
779x694 - 26KB - JPEG

入门 | 初学机器学习:直观解读KL散度的数学概
866x575 - 40KB - JPEG

入门 | 初学机器学习:直观解读KL散度的数学概
866x575 - 42KB - JPEG